08 Feb 2018
Recently I have been doing a fair amount with Fable-React-Elmish, and I have had really good results.
Quick time to production, little or no bugs. Overal I have been very happy with the toolchain. Now admittedly the apps
I have been producing are small, boring line of business apps. Basically just utilities or forms that essentailly are nothing
more than data entry. However the latest application I have had to produce was abit more involved. Basically there is a simple form
that has to query a API and then dispaly the data in a table with various levels of grouping. Armed with my recent successful experiences
with the Fable-Elmish-React toolset I was reasonably confident I could have something running in a few days. Which I did, and
I was pleased with my self.
UNTIL...
I started testing with more realistically sized datasets. And then I found out it was slow, like, really, really, slow. Over a second to render
a single key press. This was somewhat a surprise as everything you read about React says how blazing fast the Virtual DOM and rendering are.
In it's first cut I had a view which looked something like the following.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26:
27:
28:
29:
30:
31:
32:
33:
34:
|
let view model dispatch =
R.div [ClassName "col-md-12"] [
if model.Data.Length > 0
then
yield R.form [ClassName "form form-inline col-md-12"; Style [PaddingBottom "10px"]] [
R.button [ClassName "btn btn-default col-md-1";
Disabled (model.PendingChanged.Length = 0);
OnClick (fun x -> x.preventDefault(); dispatch SaveChanges)
] [unbox "Save Changes"]
R.input [ Id "selectedentity";
ClassName "form-control";
Style[MarginLeft "20px"];
Placeholder "Select Entity";
Value model.Entity]
]
yield R.div [ClassName "col-md-12 table-responsive"] [
if model.Data.Length > 0
then
yield bootstrapTable [
KeyField "id"
Data model.Data
Columns model.Columns
CellEdit (CellEditFactory(
[
"mode" ==> "click"
"afterSaveCell" ==> ignore
] |> createObj))
]
else
yield R.h1 [Style [BackgroundColor "#eeeeee"; TextAlign "center"; Height "100%"]] [R.str "No Data!"]
]
]
|
However as innocent as this looks it is going to cause react some problems. Why, well the table in this case is going to contain
52 x 31 (1612) elements. That is quiet a lot of DOM elements, and the problem in this instance is that this will get rendered on every single pass.
So how do we go about solving this. Well..
TL;DR RTFM - There is a description of this exact issue on the Elmish.React github page.
By default, every time the main update function is called (upon receiving and processing a message), the entire DOM is constructed anew and passed to React for reconciliation. If there are no changes in the model of some component, its view function will under normal circumstances not return a different result. React will then still perform reconciliation and realize that there is no need to update the component's UI. Consequently, when the DOM is sufficiently large or its construction extremely time-consuming, this unnecessary work may have noticeable repercussions in terms of application performance. Thanks to lazy views however, the update process can be optimized by avoiding DOM reconciliation and construction steps, but only if the model remains unchanged.
So lazy views are the answer. Elmish-React provides several lazy view functions. The varients without the With suffix require types with equality constraint. This means that if any property on the model changes then the DOM will be updated. This is often not the behaviour you desire, since it is unlikely you will interact with your UI without changing your model. To this end you have two choices, create a lazyView component and pass the specific property or properties (as a tuple) from the model you are interested in. Or use lazyViewWith which allows us to specify the predicate that decides when we should update the containing DOM elements. In this example we'll use the latter.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26:
27:
28:
29:
30:
31:
32:
33:
34:
35:
36:
37:
38:
|
let viewLazy model dispatch =
R.div [ClassName "col-md-12"] [
if model.Data.Length > 0
then
yield R.form [ClassName "form form-inline col-md-12"; Style [PaddingBottom "10px"]] [
R.button [ClassName "btn btn-default col-md-1";
Disabled (model.PendingChanged.Length = 0);
OnClick (fun x -> x.preventDefault(); dispatch SaveChanges)
] [unbox "Save Changes"]
R.input [ Id "selectedentity";
ClassName "form-control";
Style[MarginLeft "20px"];
Placeholder "Select Entity";
Value model.Entity]
]
yield lazyViewWith
(fun oldM newM -> oldM.Entity = newM.Entity && oldM.Data = newM.Data)
(fun model ->
R.div [ClassName "col-md-12 table-responsive"] [
if model.Data.Length > 0
then
yield bootstrapTable [
KeyField "id"
Data model.Data
Columns model.Columns
CellEdit (CellEditFactory(
[
"mode" ==> "click"
"afterSaveCell" ==> ignore
] |> createObj))
]
else
yield R.h1 [Style [BackgroundColor "#eeeeee"; TextAlign "center"; Height "100%"]] [R.str "No Data!"]
]
) model
]
|
Simples. Basically we have just wrapped the div that contains the table with the lazyViewWith function, and specified the predicate that helps it decide
when to update.
With this in place, the responsiveness of the UI returned and I could breath again. I have to admit it took me way too long to figure this out considering
it is actually written on the Elmish React project home page. However on the brightside I learnt a lot about React performance analysis, mainly from this post I suggest, you read this as I found it quiet useful as well as the links at the bottom.
namespace Microsoft.FSharp.Core
type obj = System.Object
Full name: Microsoft.FSharp.Core.obj
Multiple items
val string : value:'T -> string
Full name: Microsoft.FSharp.Core.Operators.string
--------------------
type string = System.String
Full name: Microsoft.FSharp.Core.string
namespace Microsoft.FSharp.Data
type 'T list = List<'T>
Full name: Microsoft.FSharp.Collections.list<_>
module Unchecked
from Microsoft.FSharp.Core.Operators
val defaultof<'T> : 'T
Full name: Microsoft.FSharp.Core.Operators.Unchecked.defaultof
val unbox : value:obj -> 'T
Full name: Microsoft.FSharp.Core.Operators.unbox
val ignore : value:'T -> unit
Full name: Microsoft.FSharp.Core.Operators.ignore
29 Nov 2016
So recently this tweet came across my timeline.
and indeed the article is definiately worth a read. However I have recently been using both canopy and the HTML Provider together to extract auction price data from http://www.nordpoolspot.com/Market-data1/N2EX/Auction-prices/UK/Hourly/?view=table and thought it might be worth sharing some of the code I have been using. Now the problem with just using the HTML Provider to scrape this page is that you actually need the javascript on the page to execute and the HTML provider doesn't do this. Maybe this is something worth adding??
However using canopy with phantomjs we can get the javascript to execute and the table generated in the resulting HTML and therefore availble to the HTML provider. So how do we do this. Well first of all we need to find out which elements we need write a function that uses canopy to execute the page,
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
|
let getN2EXPage phantomJsDir targetUrl units withSource =
phantomJSDir <- phantomJsDir
start phantomJS
url targetUrl
waitForElement "#datatable"
if not(String.IsNullOrWhiteSpace(units))
then
let currencySelector = new SelectElement(element "#data-currency-select")
currencySelector.SelectByText(units)
let unitDisplay = (element "div .dashboard-table-unit")
printfn "%A" unitDisplay.Text
while not(unitDisplay.Text.Contains(units)) do
printfn "%A" unitDisplay.Text
sleep 0.5
printfn "%A" unitDisplay.Text
let source = withSource browser.PageSource
quit()
source
|
with this function we can now do a couple of things.
- Run a phantomjs headless browser.
- Wait for the javascript to run on the page and render the
#datatable element
- If we specify the currency to use then change the currency select element to that currency then wait again for the page to render.
- Finally pass the source of the page to a function for further processing.
So with this we can now create a snapshot of the page and dump it to a file.
1:
2:
3:
4:
5:
6:
7:
8:
|
let toolPath =
Path.GetFullPath(__SOURCE_DIRECTORY__ + "/libs/Tools/phantomjs/bin")
let writePage path content =
if File.Exists(path) then File.Delete path
File.WriteAllText(path, content)
getN2EXPage toolPath "http://www.nordpoolspot.com/Market-data1/N2EX/Auction-prices/UK/Hourly/?view=table" "GBP" (writePage "code/data/n2ex_auction_prices.html")
|
Once we have executed the above function we have a template file that we can use in the type provider to generate our type space.
1:
2:
3:
4:
5:
|
type N2EX = HtmlProvider<"data/n2ex_auction_prices.html">
let getAuctionPriceData() =
let page = getN2EXPage toolPath "http://www.nordpoolspot.com/Market-data1/N2EX/Auction-prices/UK/Hourly/?view=table" "GBP" (fun data -> N2EX.Parse(data))
page.Tables.Datatable.Rows
|
at this point we can use the HTML Provider as we normally would.
1:
2:
3:
|
let data =
getAuctionPriceData()
|> Seq.map (fun x -> x.``UK time``, x.``30-11-2016``)
|
Finally, I think it is worth noting that even though the the headers will change on the page; due to the fact that it is a rolling 9 day window. At runtime this code will carry on working as expected, because the code behind this will still be accessing the 1st and 3rd columns in the table, even though the headers have changed. However at compile time the code will fail :( because the headers and therefore the types have changed. However all is not lost, when this occurs, since the underlying type is erased to a tuple. So we could just do the following
1:
2:
3:
4:
5:
6:
|
let dataAsTuple =
getAuctionPriceData()
|> Seq.map (fun x ->
let (ukTime, _, firstData,_,_,_,_,_,_,_) = x |> box |> unbox<string * string * string * string * string * string * string * string * string * string>
ukTime, firstData
)
|
A little verbose but, hey it's another option...
namespace System
namespace System.IO
namespace Microsoft.FSharp.Data
val not : value:bool -> bool
Full name: Microsoft.FSharp.Core.Operators.not
module String
from Microsoft.FSharp.Core
val printfn : format:Printf.TextWriterFormat<'T> -> 'T
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.printfn
module Seq
from Microsoft.FSharp.Collections
val map : mapping:('T -> 'U) -> source:seq<'T> -> seq<'U>
Full name: Microsoft.FSharp.Collections.Seq.map
val box : value:'T -> obj
Full name: Microsoft.FSharp.Core.Operators.box
val unbox : value:obj -> 'T
Full name: Microsoft.FSharp.Core.Operators.unbox
Multiple items
val string : value:'T -> string
Full name: Microsoft.FSharp.Core.Operators.string
--------------------
type string = System.String
Full name: Microsoft.FSharp.Core.string
16 May 2016
Based on a gut feel and no real evidence :) apart from my own experience I would say that a large proportion of enterprise applications are essentially just some sort of Extract - Transform - Load for system A to system B.
For the sake of argument, lets say that the requirement for our application is to read data from a XML file, apply some transformation (say convert the sizes to a standard size definition S, M, L, XL) and then write it out to another CSV file.
So we can start by defining to functions to convert the sizes
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
|
let longSizeToShortSize = function
| "Small" -> "S"
| "Medium" -> "M"
| "Large" -> "L"
| "Extra Large" -> "XL"
| a -> a
let shortSizeToLongSize = function
| "S" -> "Small"
| "M" -> "Medium"
| "L" -> "Large"
| "XL" -> "Extra Large"
| a -> a
|
Now this is a fairly trivial problem, to solve and there are many ways to do it, for example a one solution might be to use a type provider and a simple CSV File representation do something like the following.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
|
type Catalog = XmlProvider<"data/lenses/source_data.xml">
let run (path:string) =
let data = Catalog.Load(path)
let data =
[|
for product in data.Products do
for catalogItem in product.CatalogItems do
for size in catalogItem.Sizes do
yield [| catalogItem.ItemNumber
product.Description
catalogItem.Gender
size.Description
longSizeToShortSize size.Description
catalogItem.Price |> string
|]
|]
Csv.Create([|"item_no"; "description"; "gender"; "size"; "short_size"; "price"|],data)
|
which gives us
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
|
item_no,description,gender,size,short_size,price
QWZ5671,FSharp Sweater,Men's,Medium,M,39.95
QWZ5671,FSharp Sweater,Men's,Large,L,39.95
RRX9856,FSharp Sweater,Women's,Small,S,42.50
RRX9856,FSharp Sweater,Women's,Medium,M,42.50
RRX9856,FSharp Sweater,Women's,Large,L,42.50
RRX9856,FSharp Sweater,Women's,Extra Large,XL,42.50
QWZ8976,FSharp T-Shirt,Men's,Medium,M,39.95
QWZ8976,FSharp T-Shirt,Men's,Large,L,39.95
RRX345,FSharp T-Shirt,Women's,Small,S,42.50
RRX345,FSharp T-Shirt,Women's,Medium,M,42.50
RRX345,FSharp T-Shirt,Women's,Large,L,42.50
RRX345,FSharp T-Shirt,Women's,Extra Large,XL,42.50
|
this implementation is all well and good for a one off. It works and is maintainable, in the sense that the code is consise and easy to follow. However there are a few issues. Since this is the enterprise, everytime a business process changes or a external regulatory change happens it is likely that the data format is going to change. It would therefore be nice to be able to change the format without having to re-write everything, in fact in enterprises I have seen release times beyond 6 weeks, so ideally we would like to push as much to scripts or configuation as we can. Also some type providers don't deal well with data that isn't in the same format (missing nodes / properties) as the example provided at compile time; Additionally because they are typically erased, reflection is out of the question, so putting the property mapping in a configuration file, is made significantly more complicated. Now of-course we can always introduce some higher-order functions to abstract aways these problems, but this would be specific to this solution. It would be nice to try and solve this in a more general way.
At F# exchange, I got into a couple of conversations around enterprise development and the patterns that I use when developing line of business applications with F#. Typically the discussion focused on the lack of need for patterns. This is mainly due F#'s strong type system and the fact that higher order functions are a pretty powerful abstraction. However one topic that promoted a certain amount of contention was Lenses or more generally Optics.
Now I can't say I am surprised by this there are a couple of reasons why,
Performance - Extra Allocations caused by individually setting properties on records can have a reasonable performace impact when used in time critical code.
No Language Support - Writing lenses for records can be a large overhead and currently there is no language support. Maybe this will happen in the future who knows??
With this considered thou, performance is often not so important in the enterprise, and even maintainability is often sacrificed in the aim of making things flexible. Now there is probably an entire other blog post around why this is the case but thats for another day. So what does an optic solution look like to this problem. Well we can first start by defining some Optics over an XML structure accessed using XPATH and one over CSV.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26:
27:
28:
29:
|
let xpath<'a> (path:string) : Lens<XElement, _> =
(fun x -> (x.XPathEvaluate(path) :?> IEnumerable).Cast<'a>().FirstOrDefault()),
(fun s x -> x)
let xml<'a> defaultV path =
let getValue defaultV (x:obj) =
match x with
| null -> defaultV
| :? XAttribute as a -> a.Value
| :? XElement as e -> e.Value
| _ -> failwithf "unable to get value on %O" x
let setValue (x:obj) v =
match x with
| :? XAttribute as a -> a.SetValue(v)
| :? XElement as e -> e.SetValue(v)
| _ -> failwithf "unable to set value %O" x
unbox<_> x
let l : Lens<_,_> = (fun x -> getValue defaultV x), (fun s x -> setValue x s)
xpath<'a> path >-> l
let xattr = xml<XAttribute>
let xelem = xml<XElement>
let csv indx (col:string) : Prism<Csv, _> =
(fun x -> x.GetValue(col,indx)),
(fun s x -> x.SetValue(col, indx, s); x)
|
Here I am using Aether a lens library by Andrew Cherry and a simple (CSV file representation)[https://gist.github.com/colinbull/60797d5377be4d841f51e4f0776a24fa] but you could use anything. If you have never used Optics or just simply want a refresher then I might suggest the guide to Aether which can be found (here)[https://xyncro.tech/aether/guides/]. Also after you have read that guide you may notice that I'm not defining Optics per se, instead I'm defining functions that return optics a subtle but important distinction.
Now we have our optics (sorry, functions) we can define our mappings. But first we need to add a little extra to our domain functions, so we can use them with Optics. In terms of transformations there are three things we can compose with Optics. Optics, Isomorphisms (a reversible function e.g. string -> char[] and char[] -> string) and Epimorphisms (which is a weaker version of the Isomorphism in that the left hand conversion may fail e.g. string -> char[] option and char[] -> string). For our little problem we only need to concern ourselves with the former since we have a total function (since we include the unknown mappings). So we can define our isomorphism as follows.
1:
2:
3:
|
let shortSize : Isomorphism<_,_> =
shortSizeToLongSize,
longSizeToShortSize
|
Now we can represent our mappings as a simple list of tuples the first item in the tuple is the optic we shall use to read the data using XPATH, the second item is the optic we shall use to set the data (pop it into our CSV file representation).
1:
2:
3:
4:
5:
6:
7:
8:
9:
|
let mappings indx =
[
xelem "NULL" "parent::catalog_item/item_number", (csv indx "item_no")
xattr "NULL" "ancestor::product/@description", (csv indx "description")
xattr "NULL" "parent::catalog_item/@gender", (csv indx "gender")
xattr "NULL" "@description", (csv indx "size")
xattr "NULL" "@description", (csv indx "short_size" >?> shortSize)
xelem "NULL" "parent::catalog_item/price", (csv indx "price")
]
|
Now we have our mappings along with our transformations we need to actually be able to run this code. This is where things get a little bit nasty.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
|
let inline etl transform load extract =
let inline getSet (get,set) load source =
let value = (Optic.get get source)
Optic.set set value load
extract()
|> Seq.indexed
|> Seq.fold (fun loader (rowNumber, x) ->
(transform rowNumber)
|> Seq.fold (fun loader mapping -> getSet mapping loader x) loader) load
|
URRGH!! WTF! But as nasty as this function looks, it is actaully quiet simple; and completely general and only needs to be written once. It simply iterates over the incoming data and applies an index to this data, this represents the row number. We then fold over this indexed data, with each fold we fold over each over the mappings, reading from the first optic supplied by the mappings list then sending the value to the second optic, because of the definition lenses of setting the value means it returns to object the value was applied to, which is then returned by the fold.
1:
2:
3:
4:
5:
|
let extract() =
let path = __SOURCE_DIRECTORY__ + "/data/lenses/source_data.xml"
XDocument.Load(path).XPathSelectElements("//catalog_item/size")
etl mappings Csv.Empty extract
|
This returns the same as out original solution which is good,
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
|
item_no,description,gender,size,short_size,price
QWZ5671,FSharp Sweater,Men's,Medium,M,39.95
QWZ5671,FSharp Sweater,Men's,Large,L,39.95
RRX9856,FSharp Sweater,Women's,Small,S,42.50
RRX9856,FSharp Sweater,Women's,Medium,M,42.50
RRX9856,FSharp Sweater,Women's,Large,L,42.50
RRX9856,FSharp Sweater,Women's,Extra Large,XL,42.50
QWZ8976,FSharp T-Shirt,Men's,Medium,M,39.95
QWZ8976,FSharp T-Shirt,Men's,Large,L,39.95
RRX345,FSharp T-Shirt,Women's,Small,S,42.50
RRX345,FSharp T-Shirt,Women's,Medium,M,42.50
RRX345,FSharp T-Shirt,Women's,Large,L,42.50
RRX345,FSharp T-Shirt,Women's,Extra Large,XL,42.50
|
and now the mapping is essentially just data. However it is still compiled, so all we have really bought ourselves is turning the mappings into a list. Or have we? Lets have a closer look.
When we defined our lenses and transformations we defined things in a very specific way. The reason for this is for composablility, the lens solution allows us to implement pretty much any mapping and transformation we want without ever changing the overall structure of the solution. If I wanted to for example write this to a .NET datatable rather than CSV file then I create a function that provides, getters and setters to an instance of a datatable replace that with the CSV ones. In addition the Optic over the datatable can then be put as a gist, shared assembly or however you use common code and re-used.
So, what do you think? Are optics worth it? In my opinion apart from the plumbing code etl function (which is written once) the rest of the code is very simple and could be read by anyone, even maybe the business; which at the end of the day is what all enterprise devs try to acheive as it makes, their lives that little bit easier :).
Many YAK's have been shorn but none hurt
namespace System
namespace System.Linq
namespace System.Collections
namespace System.Collections.Generic
namespace System.Xml
namespace Microsoft.FSharp.Linq
namespace System.Xml.XPath
module Operators
from Microsoft.FSharp.Core
namespace Microsoft.FSharp.Data
Multiple items
val string : value:'T -> string
Full name: Microsoft.FSharp.Core.Operators.string
--------------------
type string = System.String
Full name: Microsoft.FSharp.Core.string
type ResizeArray<'T> = System.Collections.Generic.List<'T>
Full name: Microsoft.FSharp.Collections.ResizeArray<_>
union case Option.Some: Value: 'T -> Option<'T>
module Array
from Microsoft.FSharp.Collections
val map : mapping:('T -> 'U) -> array:'T [] -> 'U []
Full name: Microsoft.FSharp.Collections.Array.map
union case Option.None: Option<'T>
val defaultArg : arg:'T option -> defaultValue:'T -> 'T
Full name: Microsoft.FSharp.Core.Operators.defaultArg
val failwithf : format:Printf.StringFormat<'T,'Result> -> 'T
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.failwithf
module Seq
from Microsoft.FSharp.Collections
val tryItem : index:int -> source:seq<'T> -> 'T option
Full name: Microsoft.FSharp.Collections.Seq.tryItem
val tryFindIndex : predicate:('T -> bool) -> source:seq<'T> -> int option
Full name: Microsoft.FSharp.Collections.Seq.tryFindIndex
module Option
from Microsoft.FSharp.Core
val bind : binder:('T -> 'U option) -> option:'T option -> 'U option
Full name: Microsoft.FSharp.Core.Option.bind
val toArray : source:seq<'T> -> 'T []
Full name: Microsoft.FSharp.Collections.Seq.toArray
module String
from Microsoft.FSharp.Core
val concat : sep:string -> strings:seq<string> -> string
Full name: Microsoft.FSharp.Core.String.concat
val ignore : value:'T -> unit
Full name: Microsoft.FSharp.Core.Operators.ignore
type obj = System.Object
Full name: Microsoft.FSharp.Core.obj
val unbox : value:obj -> 'T
Full name: Microsoft.FSharp.Core.Operators.unbox
val set : elements:seq<'T> -> Set<'T> (requires comparison)
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.set
val indexed : source:seq<'T> -> seq<int * 'T>
Full name: Microsoft.FSharp.Collections.Seq.indexed
val fold : folder:('State -> 'T -> 'State) -> state:'State -> source:seq<'T> -> 'State
Full name: Microsoft.FSharp.Collections.Seq.fold
24 Mar 2015
Recently Dr. James McCaffery, posted Why he doesn't like the F# language. Quite a few of his points are subjective. People have different preferences and it seems like F# and more generally functional programming takes him outside of this comfort zone. This is fine, and I have absolutly no objections about views like this. I have a similar feeling when I'm in C# or Java. I don't feel safe, or comfortable, again it is just a preference thing.
However, there are a few points raised in the blog post that I don't really agree with. I'll tackle each one seperately not to loose any context.
- F# has a tiny user base.
I did a quick search on the day I wrote this post at a job aggregation site and found 109 job listings that mentioned F#. There were over 34,000 job listings that mentioned C#. And at MSDN Magazine, where I'm the Senior Contributing Editor, our F# articles get very few reads. The tiny user base means there is relatively weak community technical support on sites like Stack Overflow, compared to mainstream languages. Additionally, unlike other languages with relatively few users (such as R), there`s no real motivation for me to adopt F# from a career point of view, because of the very limited job opportunities.
While I somewhat agree, that F# adoption in industry has been slow. I think alot of this is to do with the fact that in the early days F# wasn't pushed as a general purpose programming language. This was obviously a marketing decision made in Microsoft, for reasons that are unknown to me. This decision caused an elitist view of F# in the early days with the preception that you need a advanced degree in a mathematical subject to use it, categorising it as only being good for Data Science, Finance, Mathematics and Research. Thus these areas were the early adoptors. In fact a quick browse of the testimonials page on FSharp.org backs this up. With testimonails coming from one of these areas. There are of course some exceptions most notably the design of Louvre in Abu Dhabi and it's use at GameSys.
However this metric is only one dimension and just because there are currently only a few jobs in a language doesn't mean you should not learn it. I'm currently learning langauges like Haskell, Coq and Idris. For the latter I doubt there is a single role in this country (although I'm willing to be proved wrong on this). Why do I do this? I hear you ask. Well I believe by learning different langauges and paradigms pushes me slightly out of my comfort zone and makes me a better programmer, in which-ever language I ultimately end up coding a commercial product in.
With the commercial prospects aside a conslusion is drawn that a small user base => a weak technical community. I don't know about other languages but I can categorically say that with F# this is simply not true. In fact, as I started writing this blog post, I raised an issue in the Paket project on github and within an hour, I had a fix presented too me.
For other sites like Stack Overflow, I can't really comment on the experience as I don't tend to use it much myself. However we can use F# to do some data munging to see how the community it doing. i.e. What is the average time for questions with an accepted answer to have got that answer?
To acheive this we can download the first 10000 questions with the F# tag, and write the result of each request out to a set of files.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
|
let baseUri = "https://api.stackexchange.com/2.2/"
let [<Literal>] dataPath = __SOURCE_DIRECTORY__ + "/data/stackoverflow/"
let dataDir =
let path = new DirectoryInfo(dataPath)
if not(path.Exists)
then path.Create()
path
let getQuestions(page) =
let outputPath = new FileInfo(Path.Combine(dataDir.FullName, sprintf "questions_%d.questions" page))
if(not <| outputPath.Exists)
then
let results =
Http.RequestString(baseUri + sprintf "search?page=%d" page + "&pagesize=100&order=desc&sort=creation&tagged=f%23&site=stackoverflow")
File.WriteAllText(outputPath.FullName, results)
let writeQuestions() =
[1 .. 100] |> List.iter getQuestions
|
Next we can merge all of these questions using the Json type provider into a single list,
1:
2:
3:
4:
5:
6:
7:
8:
|
let [<Literal>] questionPath = dataPath + "questions.json"
type Questions = JsonProvider<questionPath>
let questions =
[
for file in dataDir.EnumerateFiles("*.questions") do
yield! Questions.Load(file.FullName).Items
]
|
Next up is getting the accepted answers. Firstly we build a map of the accepted answersId against the questions so we can relate them again later, then we use getAcceptedAnswers to chunk the requests and write the results out to a file. Once we have the results we again use the Json type provider to merge the results up into a single list.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26:
27:
28:
29:
30:
31:
32:
33:
34:
35:
36:
37:
|
let questionAnswerMap =
questions
|> Seq.fold (fun state question ->
match question.AcceptedAnswerId with
| Some answerId -> (answerId, question) :: state
| None -> state
) []
|> Map.ofSeq
let getAcceptedAnswers() =
let answerIds =
questionAnswerMap
|> Map.toSeq
|> Seq.map (fun (answerId,_) -> answerId.ToString())
let counter = ref 1
for answers in chunkBySize 100 answerIds do
let outputPath = new FileInfo(Path.Combine(dataDir.FullName, sprintf "answers_%d.answers" !counter))
if (not <| outputPath.Exists)
then
let answersStr = String.Join(";", answers)
let answers =
Http.RequestString(
baseUri + sprintf "answers/%s?order=desc&sort=creation&site=stackoverflow" answersStr
)
printfn "Writing answers %s" outputPath.FullName
File.WriteAllText(outputPath.FullName, answers)
incr(counter)
let [<Literal>] answersPath = dataPath + "answers.json"
type Answers = JsonProvider<answersPath>
let answers =
[
for file in dataDir.EnumerateFiles("*.answers") do
yield! Answers.Load(file.FullName).Items
]
|
Next up we pair the questions with the accepted answers.
1:
2:
3:
4:
5:
6:
7:
|
let mergeQuestionAnswers =
[
for answer in answers do
match questionAnswerMap.TryFind answer.AnswerId with
| Some question -> yield question, answer
| None -> ()
]
|
And we are now at a point where we can compute some statistics around the questions.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
|
let getTimeToClose (question : Questions.Item, answer : Answers.Item) =
(unixToDateTime answer.CreationDate).Subtract(unixToDateTime question.CreationDate).TotalHours
let statsByYear =
mergeQuestionAnswers
|> Seq.groupBy (fun (q,a) -> (unixToDateTime q.CreationDate).Year)
|> Seq.map (fun (year, data) ->
let timeToClose =
data |> Seq.map getTimeToClose
let average = timeToClose |> Seq.average
let median = timeToClose |> median
year, average, median
)
|> Seq.sortBy (fun (y, _, _) -> y)
|> Seq.toArray
|
This gives the following results.
[|(2008, 2345.916019, 1.900555556); (2009, 333.4175912, 0.4058333333);
(2010, 96.91721817, 0.5219444444); (2011, 48.4008104, 0.5786111111);
(2012, 165.2300729, 0.66); (2013, 36.97864167, 0.74);
(2014, 42.91575397, 0.6572222222); (2015, 25.93529412, 0.6344444444)|]
|
Which we can then plot using
1:
2:
3:
4:
|
(Chart.Combine [
Chart.Line(statsByYear |> Seq.map (fun (y, a, _) -> y, a), Name = "Average")
Chart.Line(statsByYear |> Seq.map (fun (y, _, m) -> y, m), Name = "Median")
]).WithLegend(true)
|
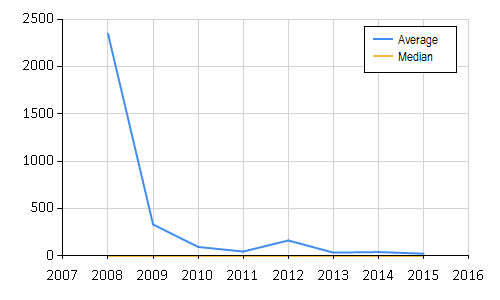
And actually we see that in 2008 when FSharp first appeared it took a long time for questions to get closed. This is the year F# was introduced and I suspect there was only a handful of people outside of Microsoft Research that actually where able to answer these questions.
However as time has progressed we see an exponential improvement it the time for questions to get answered, which typically bottoms out with an average of 25 hours and a median of about 30 mins. This is clearly a sign of a responsive community, that is indeed growing. Whats more,
I still don't think that an average of 25 hours is actually representative. In my experience I rarely use Stack Overflow for F# questions, instead I direct my questions to the fsharp github repository previously on codeplex,
the repository of the project I am using, or finally twitter with the #fsharp tag, and wait for the plethora of responses to come in from the help and very active community members. And in these domains the response time is typically around ~5 minutes.
In fact as I write this I'm wondering whether the comment
few irritatingly vocal people in the F# community implicitly try to guilt non-believers into F# adoption.
has been spurred by the willingness to help in the community. Yes there is a certain amount of advertisment that goes on for features specific to F#, but in general it is just sound fundamental programming advice. I'm fairly sure every single one of those people would offer examples in C#, Haskell or VB if asked. Anyway I digress.
The second comment that stood out for me in the post was,
- F# has no compelling technical advantage.
Some overly zealous F# fans claim that F# can do things that general purpose languages like Perl and C# can't. This all depends on how you define features of languages. But more reasonable F# proponents usually state, correctly, that F# isn't intended to replace languages like C# and that F# doesn't have any unique, magic capabilities. So, there's no technical reason for me to use F#, and the cost of context switching between the primarily procedural C# and the primarily functional F# is a huge price to pay.
I think you only have to look at type providers, which are used to analyse the Stack Overflow questions above are certainly a nice and almost unique feature. That to my knowledge only one other language has Idris. Sure you can do the analysis I have done above in C# but there will be alot more typing and additionally a lot less safety, since you will ultimately loose the strongly typed data access, that type providers offer. Moreover it is this safety that F# and statically typed functional programming languages in general offers you and makes it worth the context switch.
Since I adopted F# and functional programming it has completely changed the way I think about coding problems in all of the other languages I use, most notable C#. It has made me a better developer.
namespace Microsoft.FSharp.Data
namespace System
namespace System.IO
Multiple items
val seq : sequence:seq<'T> -> seq<'T>
Full name: Microsoft.FSharp.Core.Operators.seq
--------------------
type seq<'T> = System.Collections.Generic.IEnumerable<'T>
Full name: Microsoft.FSharp.Collections.seq<_>
module Array
from Microsoft.FSharp.Collections
val zeroCreate : count:int -> 'T []
Full name: Microsoft.FSharp.Collections.Array.zeroCreate
Multiple items
val ref : value:'T -> 'T ref
Full name: Microsoft.FSharp.Core.Operators.ref
--------------------
type 'T ref = Ref<'T>
Full name: Microsoft.FSharp.Core.ref<_>
val sub : array:'T [] -> startIndex:int -> count:int -> 'T []
Full name: Microsoft.FSharp.Collections.Array.sub
Multiple items
val int : value:'T -> int (requires member op_Explicit)
Full name: Microsoft.FSharp.Core.Operators.int
--------------------
type int = int32
Full name: Microsoft.FSharp.Core.int
--------------------
type int<'Measure> = int
Full name: Microsoft.FSharp.Core.int<_>
type DateTimeKind =
| Unspecified = 0
| Utc = 1
| Local = 2
Full name: System.DateTimeKind
field System.DateTimeKind.Utc = 1
Multiple items
val float : value:'T -> float (requires member op_Explicit)
Full name: Microsoft.FSharp.Core.Operators.float
--------------------
type float = System.Double
Full name: Microsoft.FSharp.Core.float
--------------------
type float<'Measure> = float
Full name: Microsoft.FSharp.Core.float<_>
module Seq
from Microsoft.FSharp.Collections
val toArray : source:seq<'T> -> 'T []
Full name: Microsoft.FSharp.Collections.Seq.toArray
val sort : array:'T [] -> 'T [] (requires comparison)
Full name: Microsoft.FSharp.Collections.Array.sort
val floor : value:'T -> 'T (requires member Floor)
Full name: Microsoft.FSharp.Core.Operators.floor
val ceil : value:'T -> 'T (requires member Ceiling)
Full name: Microsoft.FSharp.Core.Operators.ceil
Multiple items
type LiteralAttribute =
inherit Attribute
new : unit -> LiteralAttribute
Full name: Microsoft.FSharp.Core.LiteralAttribute
--------------------
new : unit -> LiteralAttribute
val not : value:bool -> bool
Full name: Microsoft.FSharp.Core.Operators.not
val sprintf : format:Printf.StringFormat<'T> -> 'T
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.sprintf
Multiple items
module List
from Microsoft.FSharp.Collections
--------------------
type List<'T> =
| ( [] )
| ( :: ) of Head: 'T * Tail: 'T list
interface IEnumerable
interface IEnumerable<'T>
member GetSlice : startIndex:int option * endIndex:int option -> 'T list
member Head : 'T
member IsEmpty : bool
member Item : index:int -> 'T with get
member Length : int
member Tail : 'T list
static member Cons : head:'T * tail:'T list -> 'T list
static member Empty : 'T list
Full name: Microsoft.FSharp.Collections.List<_>
val iter : action:('T -> unit) -> list:'T list -> unit
Full name: Microsoft.FSharp.Collections.List.iter
val fold : folder:('State -> 'T -> 'State) -> state:'State -> source:seq<'T> -> 'State
Full name: Microsoft.FSharp.Collections.Seq.fold
union case Option.Some: Value: 'T -> Option<'T>
union case Option.None: Option<'T>
Multiple items
module Map
from Microsoft.FSharp.Collections
--------------------
type Map<'Key,'Value (requires comparison)> =
interface IEnumerable
interface IComparable
interface IEnumerable<KeyValuePair<'Key,'Value>>
interface ICollection<KeyValuePair<'Key,'Value>>
interface IDictionary<'Key,'Value>
new : elements:seq<'Key * 'Value> -> Map<'Key,'Value>
member Add : key:'Key * value:'Value -> Map<'Key,'Value>
member ContainsKey : key:'Key -> bool
override Equals : obj -> bool
member Remove : key:'Key -> Map<'Key,'Value>
...
Full name: Microsoft.FSharp.Collections.Map<_,_>
--------------------
new : elements:seq<'Key * 'Value> -> Map<'Key,'Value>
val ofSeq : elements:seq<'Key * 'T> -> Map<'Key,'T> (requires comparison)
Full name: Microsoft.FSharp.Collections.Map.ofSeq
val toSeq : table:Map<'Key,'T> -> seq<'Key * 'T> (requires comparison)
Full name: Microsoft.FSharp.Collections.Map.toSeq
val map : mapping:('T -> 'U) -> source:seq<'T> -> seq<'U>
Full name: Microsoft.FSharp.Collections.Seq.map
module String
from Microsoft.FSharp.Core
val printfn : format:Printf.TextWriterFormat<'T> -> 'T
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.printfn
val incr : cell:int ref -> unit
Full name: Microsoft.FSharp.Core.Operators.incr
val groupBy : projection:('T -> 'Key) -> source:seq<'T> -> seq<'Key * seq<'T>> (requires equality)
Full name: Microsoft.FSharp.Collections.Seq.groupBy
val average : source:seq<'T> -> 'T (requires member ( + ) and member DivideByInt and member get_Zero)
Full name: Microsoft.FSharp.Collections.Seq.average
val sortBy : projection:('T -> 'Key) -> source:seq<'T> -> seq<'T> (requires comparison)
Full name: Microsoft.FSharp.Collections.Seq.sortBy
06 Nov 2014
Over the last few years, I have been quite taken by the actor model of computing. Although not a silver bullet it does tend to make concurrent programming orders of magnitude easier to reason about. If you have never heard of Actors then an actor as defined by wikipedia is as follows
The Actor model adopts the philosophy that everything is an actor. This is similar to the everything is an object philosophy used by some object-oriented programming languages, but differs in that object-oriented software is typically executed sequentially, while the Actor model is inherently concurrent.
An actor is a computational entity that, in response to a message it receives, can concurrently:
- send a finite number of messages to other actors;
- create a finite number of new actors;
- designate the behavior to be used for the next message it receives.
I also encourage you to look at Erlang/Elixir, Akka, Orleans and the MailboxProcessor<'a> in FSharp.Core.
Cricket, formerly FSharp.Actor, is yet another actor framework. Built entirely in F#, Cricket is a lightweight alternative to Akka et. al. To this end it is not as feature rich as these out of the box, but all of the core requirements like location transpancy, remoting, supervisors, metrics and tracing. Other things like failure detection and clustering are in the pipeline it is just a question of time.
Some key links for Cricket:
The nuget package, contains a single library Cricket.dll and a reference to FsPickler, which is used for serailization.
The following example, creates a echo actor using cricket.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
|
#I "../packages"
#r "FsPickler/lib/net45/FsPickler.dll"
#r "Cricket/lib/Cricket.dll"
open Cricket
ActorHost.Start()
let echo =
actor {
name "echo"
body (
let rec loop() = messageHandler {
let! msg = Message.receive()
printfn "%s" msg
return! loop()
}
loop())
} |> Actor.spawn
|
A couple of things are happening in the code above. Firstly, we start an ActorHost which sets up an environment within the current process for the actor to live in. Next we define the actor, we give it a name echo and a body. The body is actually the only thing that is required. If the name is omitted then it is assinged as a Guid. All the body of an actor consists of is a recursive function, that describes how to handle the messages posted to the actor. In this case we simply print a message to the console. Once we have defined the actor we then spawn it using Actor.spawn. After an actor has been spawned it is ready to consume messages. We can send messages directly to the actor by using the ActorRef that is returned by Actor.spawn.
1:
|
echo <-- "Hello, from Cricket"
|
Alternatively we can resolve the actor by name and send the message that way.
1:
|
"echo" <-- "Hello, from Cricket"
|
From these basic beginings we can build entire systems using actors. These systems can be spread over multiple machines and as long as the underlying message transport supports it different data-centres. To make our echo actor distributed, we don't have to change the implementation of the actor. All we have to do is enable remoting on the actor host.
1:
2:
3:
4:
5:
6:
7:
8:
|
//Node1 host configuration
ActorHost.Start()
.SubscribeEvents(fun (evnt:ActorEvent) -> printfn "%A" evnt)
.EnableRemoting(
[new TCPTransport(TcpConfig.Default(IPEndPoint.Create(12002)))],
new BinarySerializer(),
new TcpActorRegistryTransport(TcpConfig.Default(IPEndPoint.Create(12003))),
new UdpActorRegistryDiscovery(UdpConfig.Default(), 1000))
|
All we have done is enchance the ActorHost with a collection of message transports, a serializer, a registry transport and a way for the actors to discover each other. Similar setif we used the same setup on another node.
1:
2:
3:
4:
5:
6:
7:
8:
|
//Node2 host configuration
ActorHost.Start()
.SubscribeEvents(fun (evnt:ActorEvent) -> printfn "%A" evnt)
.EnableRemoting(
[new TCPTransport(TcpConfig.Default(IPEndPoint.Create(12004)))],
new BinarySerializer(),
new TcpActorRegistryTransport(TcpConfig.Default(IPEndPoint.Create(12005))),
new UdpActorRegistryDiscovery(UdpConfig.Default(), 1000))
|
then we can on node 2 resolve any actors on node 1, using the example above. Alternatively if I had 10 nodes but wanted to resolve the echo actor on node 9, I could do something like the following
1:
|
"node9@*/echo" <-- "Hello, from Cricket"
|
This would then resolve the actor on node9. If we had kept the original query which was simply echo then this would resolve any actor named echo all of the nodes participating in the group. For more details on remoting and a link to an example see here
val printfn : format:Printf.TextWriterFormat<'T> -> 'T
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.printfn
